동기
무료한 일상을 즐기던 나에게

어느 날 아는 형에게서 연락이 왔다.

그렇게 시작된 네이버 뉴스 기사 크롤링 프로그램!
좀 가볍게 만들어 보고 싶은 욕구가 생겼다. 헤헤 만들어 봐야징
요구 사항

Default view
Gallery
Search
UI 설계
기본 바탕 : console 을 이용하기 때문에 직관적인 글자와 칸 구분만 존재하도록 하면 된다.
1.
사용자 입력
•
검색어
•
페이지 수
2.
알림
•
검색어 입력 요청
•
페이지 수 입력 요청
•
크롤링 상태 중 알림
•
excel 파일 생성 알림
•
작업 완료 알림
•
작업 중 에러 및 예외 발생 알림
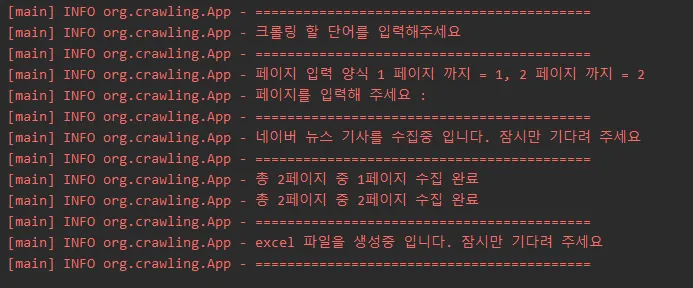
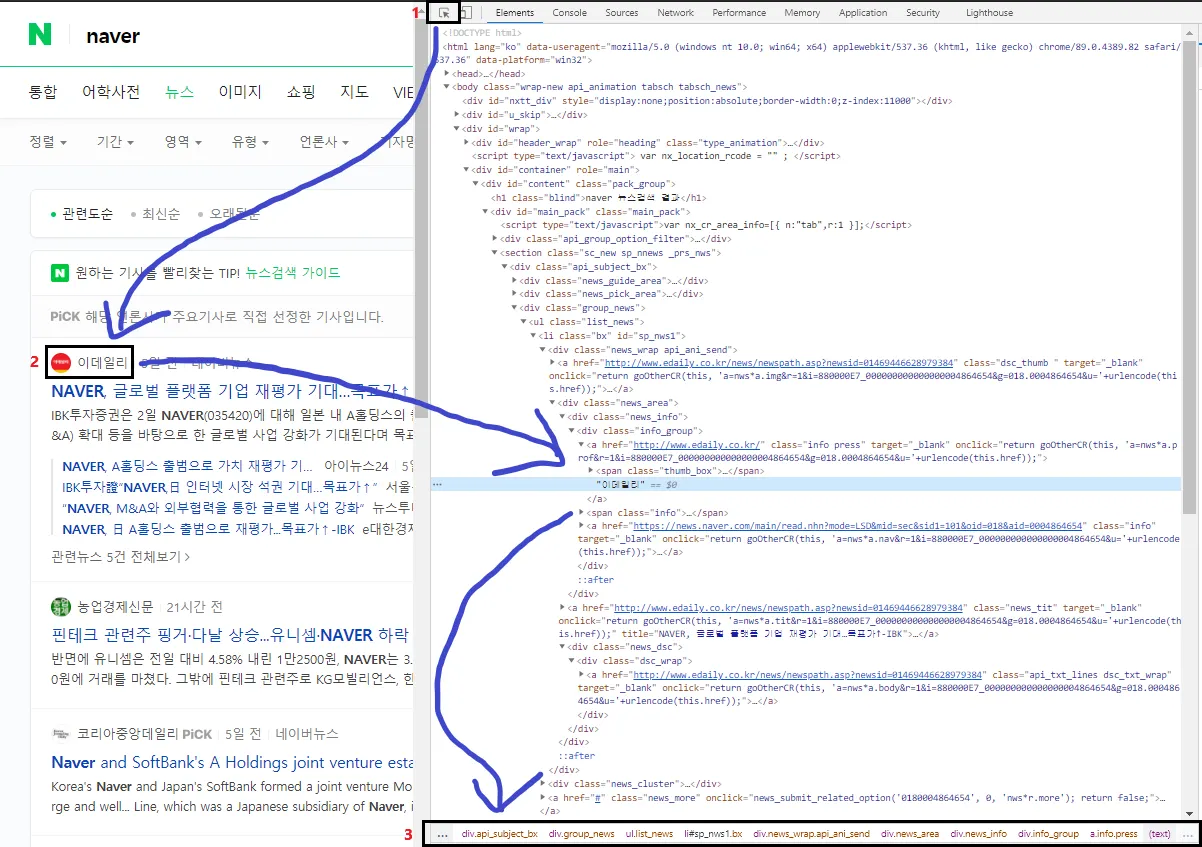
크롤링 분석
필요 데이터 위치 분석
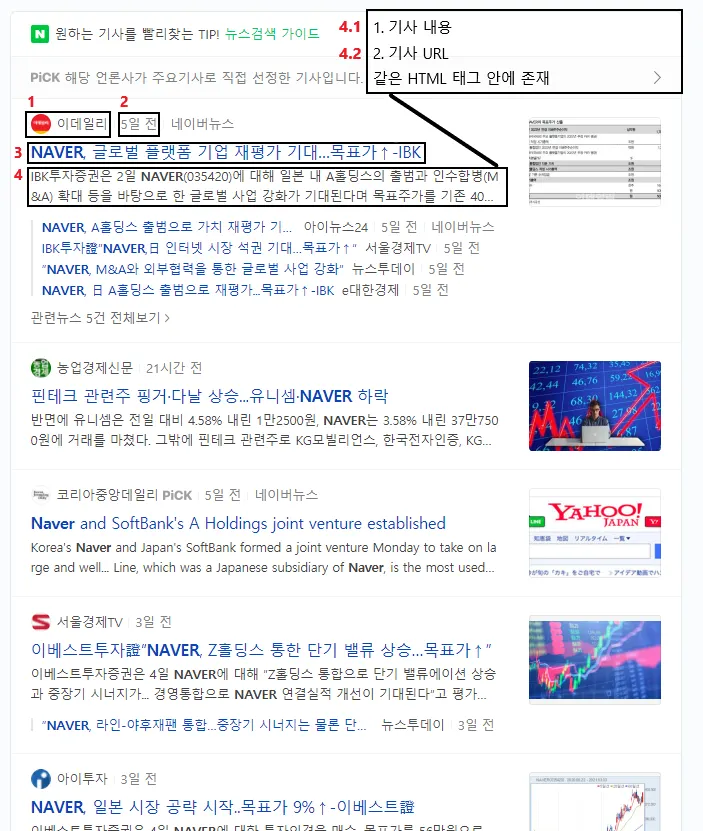
HTML 태그 분석
공통 노드
div#wrap >
div#container >
div#content.pack_group >
div#main_pack.main_pack >
section.sc_new.sp_nnews._prs_nws >
div.api_subject_bx >
div.group_news >
ul.list_news >
1. 언론사 명
공통노드 >
li.bx >
div.news_wrap.api_ani_send >
div.news_area >
div.news_info >
div.info_group >
a.info.press (TEXT)
2. 날짜 노드
공통 노드 >
li.bx >
div.news_wrap.api_ani_send >
div.news_area >
div.news_info >
div.info_group >
span.info (TEXT)
3. 기사 제목
공통 노드 >
li.bx >
div.news_wrap.api_ani_send >
div.news_area >
a.news_tit (TEXT)
4 기사 내용, URL
공통 노드 >
li.bx >
div.news_wrap.api_ani_send >
div.news_area > div.news_dsc >
div.dsc_wrap >
(4.1) a.api_txt_lines.dsc_txt_wrap (TEXT) -> URL
(4.2) a.api_txt_lines.dsc_txt_wrap (attr : href) -> URL
HTML
복사
알아두면 좋은 상식

1~3 순으로 가면서 3에서 HTML 노드 경로가 나온다
최종 소스 코드
패키지 구조
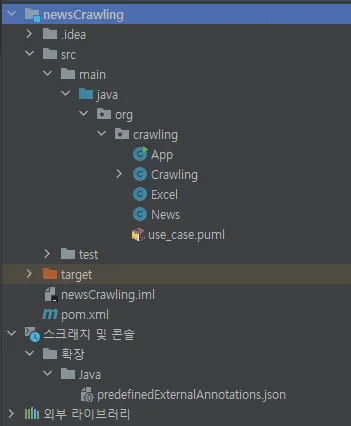
App.CLASS 보기
Crawling.CLASS 보기
Excel.CLASS 보기
News.CLASS 보기
pom.xml dependencies
미흡한 점
1.
아직 오류 처리에서 어떤 오류로 처리 해야 할지 공부가 필요한 것 같다.
2.
메모리를 얼마나 차지하는지 확인하는 방법도 배울 필요성이 있다.
3.
log ? system.out.println 사실 어떤것이 더 맞는지에 대해서는 아직도 의문이다. 콘솔에 보여주기 위한 용도이자 확인용도? 의 개념으로 사용하긴 했지만 에러에도 사용했다. 이럴땐 뭘쓰는게 더 맞는지 공부할 필요가 있다.
4.
String, StringBuilder 구분해서 사용해보려고 노력했다. 근데 아직 잘 사용했는지에 대해서는 의문이다.
5.
Scanner, BufferedReader 현재는 Scanner를 썻다. 근데 BufferedReader가 더 빠른것은 알고 있다. 이점에서 조금 수정이 필요하다.
6.
경로 구하는 도중에 네이버는 날짜가 "1일 전, 56분 전, 14시간 전" 이 포함되어 있고 가끔 "A19면 1단" 같은 것이 먼저 나올때가 있었다. 이걸 해결하기 위해서 상위로 이동하여 자식 태그 개수를 구하고 그 개수의 2번째 값을 찾아왔다. 그 때문에 상위 태그 경로를 쓰고 있다. 하위에서 한번 써줄 것이 중복이 생겼다. 해결해야 한다.
7.
date 와 같은 시간을 다룰때 정형화된 방식이 필요할 것 같다. 일단은 String으로 처리했다. 물론 이렇게 하면 안될 것 같다는 생각이 든다.
결과
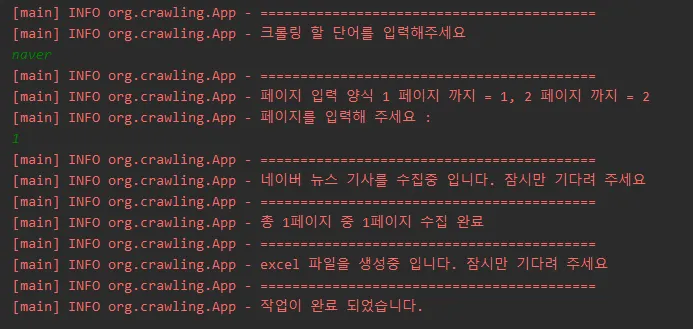
실행
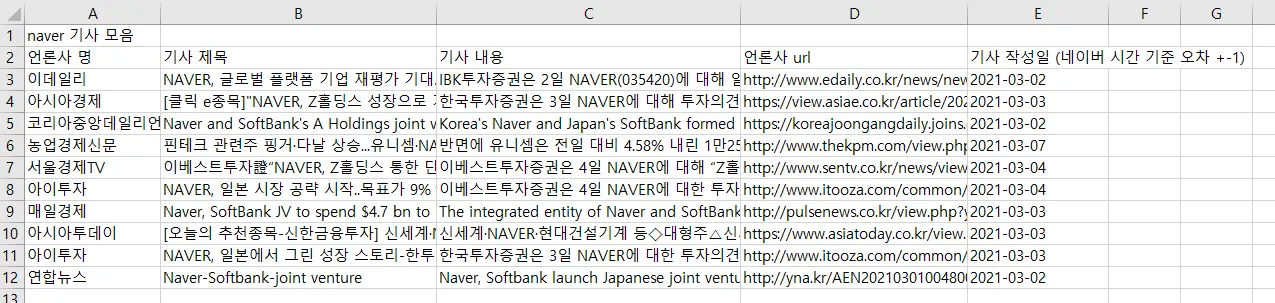
결과 excel
exe 파일

exe 파일 변환 : https://jinunthing.tistory.com/7