
우리는 어떤 처리에 있어서 많은 작업을 소요하고 있다. 가령 어떤 요리 리스트에서 칼로리가 400이상인 요소들을 찾아낸다고 가정해보자. 그럼 for문을 이용하여 리스트를 순회하며 if문을 통하여 400인 요소를 찾아낼 것이다. 하지만 SQL질의 문에서는 어떠한가? 우리는 단순히 400이상인 요소를 찾아 돌라고 질의하면 된다. 코드로 보자면 SELECT 요리 FROM 요리_리스트 WHERE 칼로리 ≥ 400; 이 될 것이다. 근데 중요한 차이점이 있다. SQL에서는 순회라는 작업이 없다. 이미 눈치챈 사람도 있을 것이다. 이러한 구현은 자동으로 제공된다. 컬렉션 즉, 자바 컬렉션 프레임워크에서도 이러한 기능을 제공한다. 이 질문의 답이 스트림이다.
스트림이란?
스트림을 이용하면 선언형 즉, 데이터를 처리하는 임시 구현 코드 대신 질의로 표현하는 방식으로 데이터를 처리할 수 있다. 또한 멀티스레드 코드를 구현하지 않아도 데이터를 투명하게 병렬로 처리할 수 있다.
만약 위의 서론에서 말한 400 칼로리 이상의 음식을 알아내고 높은 순서로 정렬해야하는 작업이 있다고 가정해보자.
public class Dish {
public enum Type{
MEAT, FISH, OTHER
}
private final String name;
private final boolean vegetarian;
private final int calories;
private final Type type;
public Dish(String name, boolean vegetarian, int calories, Type type) {
this.name = name;
this.vegetarian = vegetarian;
this.calories = calories;
this.type = type;
}
public String getName() {
return name;
}
public boolean isVegetarian() {
return vegetarian;
}
public int getCalories() {
return calories;
}
public Type getType() {
return type;
}
@Override
public String toString() {
return "Dish{" +
"name='" + name + '\'' +
", vegetarian=" + vegetarian +
", calories=" + calories +
", type=" + type +
'}';
}
}
Java
복사
public class Menu {
private final static List<Dish> DISHES = Arrays.asList(
new Dish("pork", false, 800, Dish.Type.MEAT),
new Dish("beef", false, 700, Dish.Type.MEAT),
new Dish("chicken", false, 400, Dish.Type.MEAT),
new Dish("rice", true, 350, Dish.Type.OTHER),
new Dish("season fruit", true, 120, Dish.Type.OTHER),
new Dish("pizza", true, 550, Dish.Type.OTHER),
new Dish("prawns", false, 300, Dish.Type.FISH),
new Dish("salmon", false, 450, Dish.Type.FISH)
);
public static void main(String[] args) {
/*기존 자바 8버전 이전 코드*/
List<Dish> lowCaloricDishs = new ArrayList<>();
for (Dish dish : DISHES) {
if (dish.getCalories() >= 400){
lowCaloricDishs.add(dish);
}
}
lowCaloricDishs.sort(new Comparator<Dish>() {
@Override
public int compare(Dish d1, Dish d2) {
return Integer.compare(d2.getCalories(), d1.getCalories());
}
});
for (Dish dish : lowCaloricDishs){
System.out.println(dish.toString());
}
/*자바 8버전 이후 코드*/
List<Dish> lowCaloricDishs = DISHES.stream()
.filter(dish -> dish.getCalories() >= 400)
.sorted(comparing(Dish::getCalories).reversed())
.collect(Collectors.toList());
lowCaloricDishs.forEach(dish -> System.out.println(dish.getCalories()));
}
}
/*
result
Dish{name='pork', vegetarian=false, calories=800, type=MEAT}
Dish{name='beef', vegetarian=false, calories=700, type=MEAT}
Dish{name='pizza', vegetarian=true, calories=550, type=OTHER}
Dish{name='salmon', vegetarian=false, calories=450, type=FISH}
Dish{name='chicken', vegetarian=false, calories=400, type=MEAT}
*/
Java
복사
놀랄정도로 많은 코드가 줄어든다. 부가적으로 우리는 "질의"를 이용하여 컬렉션 데이터를 검색하고 추출하고 병합하여 데이터를 만들었다.
우리는 이제 filter, sorted, map, collect.... 와 같은 고수준 빌딩 블록으로 특정 스레딩 모델에 제한되지 않고 자유롭게 어떤 상황에서든 질의문을 이용하여 데이터를 빠르게, 투명하게 뽑아낼 수 있다.
자바 8의 스트림을 다음과 같은 특징으로 요약할 수 있다.
•
선언형 : 더 간결하고 가독성이 좋아진다
•
조립할 수 있음 : 유연성이 커진다.
•
병렬화 : 성능이 좋아진다.
스트림 시작하기

스트림이란 정확히 뭘까? "데이터 처리 연산을 지원하도록 소스에서 추출된 연속된 요소"라고 정의한다. 필자의 생각으로는 어려운 말보다는 쉽게 "서랍에서 물건하나 꺼낸 것" 이라는 생각을 했다.
스트림의 정의에서 연속된 요소, 소스, 데이터 처리 연산라는 말을 유심히 생각할 필요 있다.
•
연속된 요소 : 컬렉션은 자료구조이므로 컬렉션에서는 복잡성과 관련된 요소 저장 및 접근 연산이 주를 이룬다. 스트림은 filter, sorted, map .... 등 표현 계산식이 주를 이룬다. 즉, 컬렉션의 주 관심사는 데이터이고 스트림의 주관심사는 계산이다. 이걸 다시 쉬운 말로 표현 한다면 물건의 정의는 책이 될 수도 있고 여러가지가 될 수 있다. 책이라고 가정한다면 책이 컬렉션이다. 하지만 스트림의 관심사는 "몇페이지를 볼까?" 이다.
•
소스 : 스트림은 컬렉션, 배열, I/O자원 등의 데이터 제공 소스로부터 데이터를 소비한다. 또한 정렬된 컬렉션으로 스트림을 생성하면 정렬이 그대로 유지된다. 즉, 위의 쉬운 말로 풀이해보면 서랍에서 책을 꺼내면 그 책을 그대로 받는다는 것이다.
•
데이터 처리 연산 : 데이터베스와 비슷한 연산을 지원한다. filter, map, reduce 등등으로 데이터를 조작할 수 있다. 스트림은 순차적 또는 병렬로도 실행할 수 있다. 쉬운 말로 풀이 해보자면 "꺼낸다"의 정의가 양팔이 될 수도 아니면 다른 사람의 손을 빌리는 것일 수 있다는 것이다.
특징
•
파이프라이닝 : 스트림 연산은 연산끼리의 거대한 파이프라인을 형성할 수 있다. 그 덕분에 게으름, 쇼트 서킷 같은 최적화도 이룰 수 있다.
•
내부 반복 : 반복자를 이용해서 명시적으로 반복하는 컬렉션과 달리 스트림은 내부 반복을 지원한다. 명시적 반복이란 자바 8버전 이전 버전처럼 for을 쓰는 것을 말한다. 그게 필요 없어지는 것이다.
•
데이터 구조가 아니다. 데이터의 흐름이다.
•
데이터를 변경하지 않고 결과를 새로운 스트림에 저장한다.
•
필요한 데이터만 메모리에 로드해 처리한다. (컬렉션은 모든 데이터를 메모리에 로드해 처리)
•
Iterator처럼 데이터에 1번만 접근한다. (추가적은 접근을 위해서는 스트림을 새로 생성해 접근)
스트림과 컬렉션
데이터를 언제 계산하느냐가 컬렉션과 스트림의 가장 큰 차이다. 컬렉션의 경우 현재 자료구조가 포함하는 모든 값을 메모리에 저장한다. 즉, 컬렉션의 모든 요소는 컬렉션에 추가하기 전에 계산되어야 한다. 반면 스트림은 이론적으로 요청할 때만 요소를 계산하는 고정된 자료구조다. 이 말인 즉, 컬렉션은 삽입 삭제가 가능하다. 필자의 생각을 더하면 메모리에 모든 저장 영역을 알고 있기 때문에 가능한 것이라 생각된다. 하지만 스트림의 경우 반대로 삽입, 삭제가 불가능하다. 이유는 메모리의 모든 저장 영역을 스트림 자신도 어디에 저장될지 모르기 때문이다.
메모리 관점에서 생각하는게 좋을 것 같다. 컬렉션은 메모리라는 하나에 박스에 데이터를 다 채워야만 컬렉션 연산을 실행 할 수 있다. 하지만 스트림은 박스에 데이터를 하나만 채워도 가져가서 연산을 해준다.
외부 반복과 내부 반복
외부 반복 : for-each 와 같은 반복문의 명시적 사용
내부 반복 : 반복을 알아서 처리하고 결과 스트림 값을 어딘가에 저장해주는 것
public static void main(String[] args) {
/* 자바 8버전 이전 코드 외부반복 */
Iterator<Dish> dishes = DISHES.iterator();
while (dishes.hasNext()){
Dish dish = dishes.next();
System.out.println(dish.toString());
}
/* 자바 8버전 이후 코드 내부반복 */
DISHES.stream().forEach(dishe ->
System.out.println(dishe.toString())
);
}
Java
복사
스트림 연산
스트림 인터페이스의 연산은 크게 두 가지로 구분할 수 있다.
•
중간 연산 : filter, map, limit는 서로 연결되어 파이프라인을 형성한다.
•
최종 연산 : collect로 파이프라인을 실행한 다음 닫는다.
중간 연산
public static void main(String[] args) {
DISHES.stream()
.filter(dish -> {
System.out.println("filtering : " + dish.getName());
return dish.getCalories() > 400;
}) // 필터링한 요리명 출력
.map(dish -> {
System.out.println("mapping : " + dish.getName());
return dish.getName();
}) // 추출한 요리명 출력
.limit(3)
.peek(System.out :: println)
.collect(Collectors.toList());
}
/*
result
filtering : pork // filtering
mapping : pork // mapping
pork // collect
filtering : beef
mapping : beef
beef
filtering : chicken
filtering : rice
filtering : season fruit
filtering : pizza
mapping : pizza
pizza
*/
Java
복사
중요한 점은 중간 연산의 중요한 특징은 단말 연산(최종연산)을 스트림파이프라인에 실행하기 전까지는 아무 연산도 수행하지 않는 것이다. 이유는 filtering → mapping → collect 이런순서로 진행되면서 단 한번도 pork 수행중 beef가 끼어들지 않는다는 것이다.
초기에 말했던 특징 중 하나인 데이터 흐름을 나타내는 걸로도 알 수 있다.
// 여기서 드는 의문점. 이러한 코드도 동일하지 않은가?
// 스트림을 꼭 선택해야하는 것인가?
List<String> names = new ArrayList<>();
for (Dish dish : DISHES){
if (dish.getCalories() >= 400 && names.size()<3){
System.out.println("filtering : " + dish.getName());
System.out.println("mapping : " + dish.getName());
names.add(dish.getName());
}else{
break;
}
}
System.out.println(names.toString());
Java
복사
최종연산
최종연산은 스트림 파이프라인에서 결과를 도출한다. 마지막 return의 타입에 맞추어 스트림이외의 결과를 반환한다.
스트림 이용하기
스트림의 이용 과정은 세 가지로 요약할 수 있다.
•
질의를 수행할 데이터 소스
•
스트림 파이프라인을 구성할 중간 연산 연결
•
스트림 파이프라인을 실행하고 결과를 만들 최종연산
이제부터는 스트림에 존재하는 메소드를 이용한 방법들을 소개한다.
필터링
//필터링 예제
public class Filtering {
static List<Dish> dishes = Dish.DISHES;
public static void main(String[] args) {
vefitarianFiltering();
uniqueFiltering();
}
// Predicate Filtering
public static List<Dish> vefitarianFiltering(){
return dishes.stream()
.filter(Dish::isVegetarian) // Filter
.collect(Collectors.toList());
}
// 고유 요소 필터링 중복제거
public static List<Dish.Type> uniqueFiltering(){
return dishes.stream()
.filter(Dish::isVegetarian)
.map(Dish::getType)
.distinct()
.collect(Collectors.toList());
}
}
Java
복사
스트림 슬라이싱, 스트림 축소, 요소 건너뛰기
// takeWhile 을 이용한 스트림 슬라이싱 방법
// dropWhile 을 이용한 스트림 슬라이싱 방법
// limit 를 이용한 스트림 축소 방법
// skip 을 이용한 요소 건너 뛰기 방법
public class TakeAndDropWhile {
static List<Dish> dishes =
Dish.DISHES.stream()
.sorted(Comparator.comparing(Dish::getCalories))
.collect(Collectors.toList());
public static void main(String[] args) {
takewhile();
dropwhile();
limit();
skip();
}
/*
주목해야할 점은 takeWhile에서의 동작이다.
loop에서 300이상인 값을 만나면 그대로 종료된다. // 거짓인 순간 참을 반환
이를 활용할 수 있는 방법이 무엇일까?
바로 정렬이다. 정렬했을때는 내가 지정한 값을 순차적으로 접근할 수 있다.
그럼 결국 내가 찾고자 하는 값에 인접하면 바로 종료가 되면 되는 것이다. // 거짓인 순간
if break 와 같은 기능이다.
*/
// 말그대로 참인것만 가져감
public static List<Dish> takewhile(){ // takeWhile 자바 9버전 이상
return dishes.stream()
.takeWhile(dish -> { // 참 인것만 반환
System.out.println(dish.toString());
return dish.getCalories() < 300; // 거짓이 되는 시점 종료
})
.collect(Collectors.toList());
}
// 말그대로 거짓인건 버림
public static List<Dish> dropwhile(){ // dropWhile 자바 9버전 이상
return dishes.stream()
.dropWhile(dish -> { // 참 인것만 반환
System.out.println(dish.toString());
return dish.getCalories() < 300; // 참이되는 순간종료 거짓은버림
})
.collect(Collectors.toList());
}
// 스트림 축소
public static List<Dish> limit() {
return dishes.stream()
.limit(3) // 3개까지만 반환 0~2 라는 생각이든다
.collect(Collectors.toList());
}
// 요소 건너 뛰기
public static List<Dish> skip() {
return dishes.stream()
.skip(2) //배열 인덱스 0,1 번을 건너뛰고 스트림 반환
.collect(Collectors.toList());
}
}
Java
복사
(번외) takeWhile, dropWhile?의 동작 이상?연습 문제
public static void main(String[] args) {
List<Dish> meatFilterSizeTwo = example();
meatFilterSizeTwo .forEach(s -> System.out.println(s.toString()));
}
// 처음 두 고기 요리를 필터링 하시오!
public static List<Dish> example() {
return dishes.stream()
.filter(dish -> dish.getType() == Dish.Type.MEAT)
.limit(2)
.collect(Collectors.toList());
}
Java
복사
매핑
sql에서는 테이블의 특정 열만 선택할 수 있는 기능이 있다. 이렇듯 데이터를 선택하고 가져오는 작업은 데이터 처리과정에서 자주 수행되는 연산이다. java도 List.get(index) 이러한 구문처럼 특정한 데이터를 가져올 수 있다. 스트림에도 이런기능이 있을까? 당연히 존재한다. 스트림을 배우는 입장에서 스트림 안에서 스트림의 각요소를 가져오는 작업을 배워본다.
map
함수를 인수로 받는 map 메서드를 지원한다. map의 경우에는 인수로 제공된 함수는 각 요소에 적용되며 함수를 적용한 결과가 새로운 요소로 매핑된다. 즉, 기존값을 고쳐서 요소로 매핑이 아닌 새로운 버전을 만든다라는 개념에 가깝다. 그래서 변환에 가까운 매핑이라 많이 이야기한다.
// 만약 우리의 dishs 에서 이름 메뉴이름의 길이만 들어있는 list를 생성하고 싶다면?
public static List<Integer> map() {
return dishes.stream()
.map(Dish::getName) // String 형태의 버전
.map(String::length) // Integer 형태의 버전
.collect(Collectors.toList());
}
Java
복사
스트림 평면화
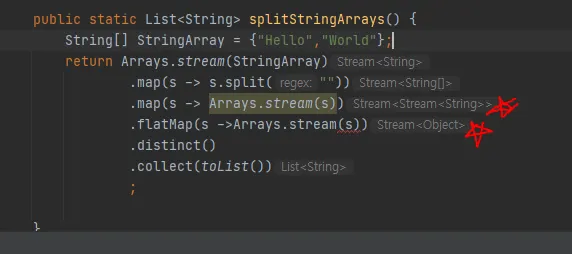
평면화가 뭘까? 에 대한 고민을 많이 했다. 우리는 stream을 이용하여 코딩을 하다보면 하나의 문제에 봉착하게 된다. 그 문제를 풀며 알게 된 평면화 과정이다.
/*
[Hello, World]를 나는 [H,e,l,o,W,r,d] 의 형식으로 출력하고 싶다.
하지만 이렇게 만들면 문제가 생긴다. return형을 잘보자 List<String[]> 이다. 이렇게
return 이 이루어진다면 어떤일이 벌어질까?
[ [H, e, l, l, o],[W, o, r, l, d] ] 아마 이렇게 출력될 것이다. 그럼 우리가
원하는 방식으로 가능하려면 어떻게 해야할까?
정답은 flatMap이다.
플랫맵은 필자의 이해로는 오선지의 플랫과 같은 역활인 것 같다.
map은 앞에 플랫, 샾이 없다 말그대로 같은 선상의 변경이다.
앞서말한 버전이 변경되는 것이다.
잘못 이해한 부분 -------------------------------------------------------------
flatMap의 경우에는 음악시간을 생각해보자 플랫이 들어가면 어떤가? 반음이 내려간다.
이렇듯 List<String[]> 의 반음을 내리는 것이라고 판단했다.
여기서 반 즉, List안에서 반을 내리면 string[] 이 존재한다. 그럼 flatMap에서 존재하는
반음은 Stream<String[]>이 아닌 String[] 이 된다.
왜 Stream이 붙는지 이해 못했다. 그래서 찾아들어가보니
<R> Stream<R> flatMap(Function<? super T, ? extends Stream<? extends R>> mappe
r);
<R> Stream<R> map(Function<? super T, ? extends R> mapper);
이렇게 둘다 stream 형태로 반환한다.
이렇게 보면 map은 말그대로 T 를 R 로 변환하여 stream을 감싼 것이고
flatMap의 경우에는
잘못 이해한 부분 -------------------------------------------------------------
제대로 된 이해
앞서 설명한 것은 초기에 잘못이해한 부분이다.
T R 관계에 대해서 제대로 이해 못했던것 같다. 말그대로 String[]이라서 String[]의 작은 단위
String을 반환하는 것이 였다. 그래서 최종타입이 결정되는 것은 List<String>인 것이다.
*/
public static List<String[]> splitStringArrays() {
String[] StringArray = {"Hello","World"};
return Arrays.stream(StringArray)
.map(s -> s.split(""))
//.flatMap(Arrays::steam) 리턴 Stream<String> 최종 리턴 List<String>
.distinct()
.collect(toList())
;
}
Java
복사
검색과 매칭
특정 속성이 데이터 집합에 있는지 여부를 검색하는 데이터 처리에 이용된다.
// 검색
// anyMatch 를 이용한 방법
// allMatch 를 이용한 방법
// noneMatch 를 이용한 방법
public class SearchAndMatching {
public static List<Dish> dishs = Dish.DISHES;
public static void main(String[] args) {
vegetarianAnyMatch();
vegetarianAllMatch();
vegetarianNoneMatch();
if (vegetarianAnyMatch()){
System.out.println("Yes");
}else {
System.out.println("No");
}
}
public static boolean vegetarianAnyMatch() { // anyMatch 를 이용한 방법
System.out.println("dishs List 안에는 채식주의자가 존재합니까?");
return dishs.stream()
.anyMatch(Dish::isVegetarian); // 적어도 하나 이상 일치하는 요소가 있는지 검색
}
public static boolean vegetarianAllMatch() { // allMatch 를 이용한 방법
System.out.println("dishs List 안에는 채식주의자만 있습니까?");
return dishs.stream()
.allMatch(Dish::isVegetarian); // 모든 요소가 일치 하는지 검사
}
public static boolean vegetarianNoneMatch() { // noneMatch 를 이용한 방법
System.out.println("dishs List 안에는 채식주의자가 없습니까?");
return dishs.stream()
.noneMatch(Dish::isVegetarian); // 모든요소가 불일치 하는지 검사
}
}
/*
!쇼트서킷!
신기한 개념이다. 근데 유용하다.
만약 답지가 있다고 가정해보자! 답지는 뭘 하는 것인가? 정답만 가진 리스트다.
근데 만약 답지에 오답이 있다면 그 답지는 답지라고 불릴 수 있는가? 아니다.
답지가 아닌 답이 많이 적혀 있는 종이다.
모든 리스트의 정답이 곧 객체의 평가 요소가 된다면 차근차근 하나씩 검사하며
틀린 것이 나오면 그 객체는 틀린 객체로 평가하는 것이다.
이러한 방법을 쇼트 서킷이라고 한다.
그럼 이것이 왜 좋을까? 필자의 생각으로는 객체검사에 있어서 최악의 경우 n번만 검사
하면 되기 때문이다.
1. [1,2,3, .... 100] 최악의 경우 100번까지 돌아가는것
2. 그럼 리스트의 크기 만큼만 돌면 된다.
유용하게 쓰일만한곳
1. 정렬이 안된 리스트 : 객체를 전체로 평가할때 선정렬 후검색은 2번연산을 거침
2. 정렬을 못하는 리스트 : 리스트의 크기가 너무 클 경우
*/
Java
복사
// 검색
// findAny 를 이용한 방법
public class SearchAndMatching {
public static List<Dish> dishs = Dish.DISHES;
public static void main(String[] args) {
System.out.println(findAnyDish().get().getName());
}
public static Optional<Dish> findAnyDish() {
Optional<Dish> vegetarianDish =
dishs.stream()
.filter(Dish::isVegetarian)
.findAny(); // 임의의 요소를 반환한다.
// 그런데 Optional<Dish>는 뭘까?
return vegetarianDish;
}
}
/*
Optional<T> 클래스는 값의 존재나 부재 여부를 표현하는 컨테이너 클래스다.
쉽게 말해 만약 findAny가 아무것도 찾지못하는 상황을 가정해보고 코드를 보자. 아래
이렇듯 null은 쉽게 에러를 일으킬 수 있다. 그래서 자바 8 라이브러리 설계자는
Optional<T> 를 만든것이다.
*/
public static void main(String[] args) {
// null.getName(); 을 참조하게된다. 그럼 NullPointException 발생
System.out.println(noOptional().getName());
}
public static Dish noOptional() {
// 메뉴리스트에는 채식주의자 메뉴가 하나도 없다.
List<Dish> noneVegetarianMenuList = Arrays.asList(
new Dish("pork", false, 800, Dish.Type.MEAT),
new Dish("beef", false, 700, Dish.Type.MEAT),
);
Dish vegetarianMenu = null;
for (Dish dish : noneVegetarianMenuList) {
if (dish.isVegetarian()){ //채식 메뉴를 찾는다.
vegetarianMenu = dish;
}
}
return vegetarianMenu; //그럼 뭘 반환하는가? null 이다.
}
// Optional의 간단한 활용
public static void main(String[] args) {
System.out.println(findAnyDish().isPresent());
// 만약 내부 값이 null 이라면 true 아니라면 false 반환
findAnyDish().ifPresent(dish -> System.out.println("값이 없습니다."));
// 값이 있으면 실행되고 없다면 만약 내부 값이 null 실행되지않음
System.out.println(findAnyDish().get().toString());
// 값이 존재하면 값을 반환하고 없다면 noSuchElementException 반환
System.out.println(findAnyDish()
.orElse(new Dish("pizza", true, 550, Dish.Type.MY_DISH))
);
// 값이 있다면 값을 반환 값이 null이라면 기본,지정 값을 반환
}
// findAny, findFirst를 왜 사용하는 것일까?
public static void main(String[] args) {
findFirstItemReturnSet().collect(Collectors.toSet()).forEach(System.out::println);
System.out.println(findFirstItem().get());
}
// limit 을 이용한
public static Set<Integer> findFirstItemReturnSet() {
List<Integer> numbers = Arrays.asList(1,2,5,4,3);
Set<Integer> limit = numbers.stream()
.map(n -> n * n)
.filter(n -> n % 3 == 0)
.limit(1)
.collect(Collectors.toSet());
return limit;
}
// findFirst를 이용한
public static Optional<Integer> findFirstItem() {
List<Integer> numbers = Arrays.asList(1,2,5,4,3);
Optional<Integer> firstSquareDivisibleByThree = numbers.stream()
.map(n -> n * n)
.filter(n -> n % 3 == 0)
.findFirst();
return firstSquareDivisibleByThree;
}
/*
이러한 예제는 findFirst 와 같다. 말그대로 첫번째 요소를 반환한다. 그런데 왜?
findFirst 가 생겨난 것일까? 바로 병렬성이다. 병렬실행에서는 첫번째요소를 찾기
힘들다. 그래서 findFirst가 생겨난 것이다. 그럼 findAny는? 일치하는 임의의 요소를
반환한다. 이말인 즉, 논리적 순서를 가진 것이 아니라면 주로 findAny를 사용한다.
*/
Java
복사
리듀싱
reduce연산을 이용해서 "메뉴의 모든 칼로리의 합계를 구하시오", "메뉴 중 칼로리가 가장높은 요리는?" 과 같이 스트림의 요소를 조합해서 복잡한 질의를 표현할 수 있다.
public class reducing {
public static void main(String[] args) {
sum();
}
// 1~10까지의 합을 구하는 문제
public static void sum() {
List<Integer> numbers = Arrays.asList(1,2,3,4,5,6,7,8,9,10);
int sum = numbers.stream()
.reduce(0, (a,b) -> a+b);
/*
reduce(초기 값, (파라미터1,파라미터2) -> 초기값에 할당 );
흐름
1번 루프
a = 초기값 0
b = 요소의 첫번째 값 1
초기값 = reduce 결과 값 1 대입연산
*/
System.out.println(sum);
}
// 같은 예제 다른 반환
public static void sum() {
List<Integer> numbers = Arrays.asList(); // stream 없음
Optional<Integer> sum = numbers.stream()
.reduce((a,b) -> a+b); // 초기 값 없음
System.out.println(sum);
}
/*
왜 reduce에 초기값 설정을 안한다면 Optinal을 반환할까?
스트림에 아무요소도 없고 초기값이 없는 상황이라면 reduce는 아무것도 반환하지
못한다. 그래서 초기값이 없는 상황에서는 이를 대비해서 optional을 반환한다.
*/
}
// 연습문제
// 메뉴가 몇개 인지 카운트 하세요
public static void dishCount(){
Optional<Integer> count =
Dish.DISHES.stream()
.map(menu -> 1)
.reduce(Integer::sum);
System.out.println(count.get());
}
/*
reduce의 장점?
가변 누적자 패턴 즉, 아까와 같은 상황 sum에 합을 구해야하는 경우에는 병렬처리가 힘
들다. 그래서 fork,join 방식을 사용해야했다. 근데 이러한 처리를 reduce를 이용하면
간단히 해결할 수 있다.
*/
Java
복사
map, filter 등은 입력스트림의 각요소를 받아 결과를 출력 스트림으로 보낸다. 결국 자기자신이 가진 상태는 없다. 말 그대로 내부에서 가진 변수가 없는 것이다. 보통 상태가 없는, 즉 내부 상태를 갖지 않는(stateless operation) 연산이다.
하지만 reduce, sum, max는 연산 결과를 누적할 상태가 필요하다. 우리 예제에서는 int 를 내부상태로 사용했다. 스트림에서 처리하는 요소 수와 관계없이 내부 상태의 크기는 한정되어 있다.
반면 sorted나 distinct는 filter나 map 처럼 보일 수 있다. 하지만 근본적으로 정렬이나 중복제거의 메커니즘은 모든 과거의 이력을 알고 있어야 가능하다. 예를 들어 어떤 요소를 출력 스트림으로 추가하려면 모든 요소가 버퍼에 추가 되어 있어야 한다. 따라서 이러한 데이터 스트림의 크기가 무한이라면 문제가 생길 수 있다. 이런 연산을 내부 상태를 갖는 연산이라한다.
기본형 특화 스트림
자바 8에서는 세가지 기본형 특화 스트림을 제공한다. Int, Double, longStream 이 스트림의 특징은 오직 박싱 과정에서 일어나는 효율성과 관련 있으며 스트림에 추가 기능을 제공하지 않는다는 점이다.
int calories = Dish.DISHES.stream()
.mapToInt(Dish::getCalories) // IntStream 반환
.sum();
/*
궁금증
그럼 map에서는? 당연히 stream<Integer>로 반환 그럼 래핑이 된 상태
하지만 mapToInt의 경우 IntStream int 형으로 반환
*/
IntStream calories = Dish.DISHES.stream()
.mapToInt(Dish::getCalories);
Stream<Integer> stream = calories.boxed(); // 박싱도 가능
/*
궁금증
그럼 여기서 IntStream이 잘못작동된다면?
예를 들어 1~10 까지의 리스트의 합계를 구한다면 55다.
0인 리스트에서 합계를 구한다면 0이다.
그럼 null인 리스트에서 max를 구한다면?
0이되어야할까?
null이 되어야할까?
그래서 OptionalInt 가 존재한다. 기본특화형의 3가지버전
만약에 찾는 값이 없다면 동일하게 noSuchElementException을 발생시킨다
*/
List<String> numbers = Arrays.asList();
OptionalInt optionalInt = numbers.stream()
.mapToInt(Integer::parseInt)
.max();
System.out.println(optionalInt.getAsInt());
//숫자범위 지정
IntStream evenNumbers = IntStream
.range(1,100) // 범위 지정 가능
.filter(n -> n%2==0);
System.out.println(evenNumbers.count());
Java
복사
스트림 만들기
Stream<Integer> stream = Stream.of(1,2,3,4); // Stream<Integer>
Stream<Integer> streamEmpty = Stream.empty(); // 빈 스트림
Stream<String> var =
Stream.ofNullable(System.getProperty("nullProperty"));
// null 일수 있는 stream 만들기 그럼 반환이 empty() 빈 스트림이 된다.
Java
복사
무한 스트림
Stream.iterate(new int[]{0,1}, t -> new int[]{t[1], t[0]+t[1]})
.limit(10)
.collect(Collectors.toList())
.forEach(s -> System.out.println(s[0]+" "+s[1]));
/*
iterate 메서드는 초깃값 new int[]{0,1}과 람다를 인수로 받아 새로운
값을 끊임없이 생산한다. 그래서 람다 t -> new int[]{t[1], t[0]+t[1]}
에서 람다는 초깃값에 계속 대입된다. 이러한 무한스트림은 언바운드 스트
림이라한다.
*/
Java
복사
가변상태와 불변상태 유지
IntSupplier fb = new IntSupplier() {
private int pre = 0;
private int crr = 1;
@Override
public int getAsInt() {
int old = this.pre;
int next = this.pre + this.crr;
this.pre = this.crr;
this.crr = next;
return old;
}
} ;
IntStream.generate(fb).limit(10).forEach(System.out :: println);
/*
이렇게도 생성할 수 있다. 근데 이게 iterate를 사용할때와 무엇이
다른가? generate는 연속적으로 값을 계산하지않는다. 또한 supplier<T> 를 인수로 받아 값을
생성한다.
또한 supplier의 특성으로 가변성이 존재한다는 것이다. 그말인즉 supplier는 내부 필드정의가
가능하다. 그의미는 객체처럼 사용이가능하다는 것이다. 그럼 무슨문제?라
고 생각할 수 있다. 근데 다음과 같이 한번 출력했을경우 문제가 없다.
두번출력해도 동일한 결과가 나와야한다. 하지만 다음을 두번출력한다면
1번호출
0
1
1
2
3
5
8
13
21
34
2번호출
55
89
144
233
377
610
987
1597
2584
4181
다음과 같은 결과가 생성된다. 이의미는 매우크다 병렬처리과정에서 값이변
환될 위험이 존재한다는 점이다.
*/
Java
복사
한번은 꼭 읽어보자, 참고 포함 전부
