
Call by Value?
•
값을 호출하는 것을 의미한다. 전달 받은 값을 복사하여 처리한다. 즉, 값을 변경하여도 원본은 변경되지 않는다.
Call by Reference?
•
참조에 의한 호출을 의미한다. 전달받은 값을 직접 참조한다. 즉, 전달 받은 값을 변경할 경우 원본도 같이 변경된다.
JAVA에 Call by Reference가 있나?


•
JAVA에서 객체를 전달 받고, 그 객체를 수정하면 원본도 같이 수정되니 이것이 Call by Reference라고 생각된다.
public class Main {
static class A{
int val;
public A(int val) {
this.val = val;
}
}
public static void swap(A val1, A val2){
int val = val2.val;
val2 = val1;
val1.val = val;
}
public static void main(String[] args) {
A val1 = new A(100);
A val2 = new A(1);
System.out.printf("val1 : %d,\t val2 : %d \n",val1.val, val2.val);
swap(val1,val2);
System.out.printf("val1 : %d,\t val2 : %d \n",val1.val, val2.val);
}
}
console result
val1 : 100, val2 : 1
val1 : 1, val2 : 1
Java
복사

여기서 잘 봐야 하는 부분은 one의 val가 1로 변경되었다는 것이다. 이렇기 때문에 헷갈릴 수 있다. 하지만 one에서 val1으로 매개변수를 넘기는 과정에서 직접참조가 아닌, 주소 값을 복사해서 넘기기 때문에 이는 call by Value이다. 복사된 주소 값으로 참조가 가능하니 주소 값이 가리키는 개체의 내용이 변경되는 것이다.
이해하게 된 원리
Call by Value 값으로 호출 즉, 값을 복사한다. 원본 값에는 손상이 없다. Call by Reference 값을 직접 값을 참조한다. 즉, 원본 값에 손상이 있다. 위의 swap()문제에서는 val1이 직접 one을 참조하는 것처럼 보인다. 하지만 하지만 val2를 val1으로 변경했는데 변경되지 않는다. 이를 통해 알 수 있는 것은 원본의 값을 직접 참조 하지 않는다는 것이다. 복사하여 사용한다. 즉, val1이 one의 주소를 복사하여 들고와 사용한다는 것이다.
조금 더 설명이 잘된 그림 예시

결론적으로 val1, val2는 one, two의 주소를 복사하여 독자적으로 가지게 된다. call by value가 발생
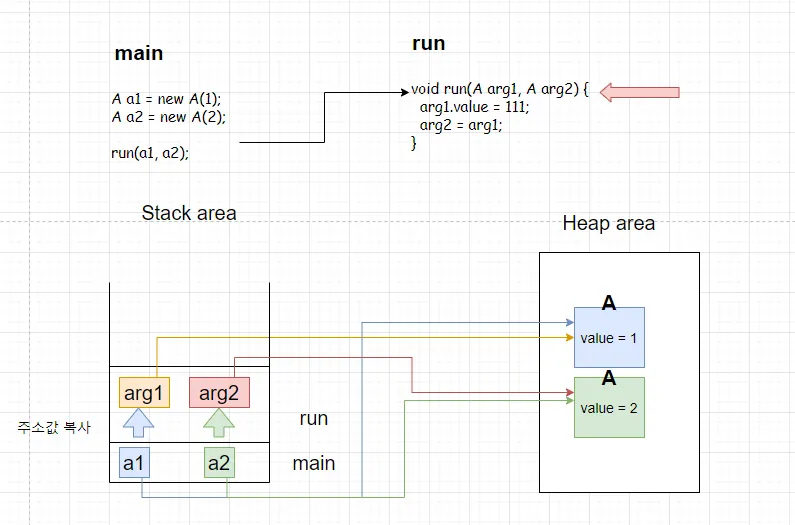
여기서 val1을 통하여 내부의 val를 변경한다면 주소 값을 통하여 객체의 값을 변경한다.

그래서 val1과 val2를 swap()해도 val2의 값이 변경되지 않았던 이유는 각기 주소값을 복사하여 사용하여 변수 별로 독립된 변수이기 때문이다.
즉, JAVA는 Call by Value 이다. 라고 해버리면 오해가 생길 수 있으니 전달방식이 Call by Value라고 하겠다.
primitive Type, Reference Type
위에서는 자바의 값 전달 방식을 알아봤다. 그럼 값의 종류에는 뭐가 있을까?
기본적으로 자바에서는 데이터 타입이 크게 두 가지 원시 타입(primitive Type), 참조 타입(Reference Type)이 있다.
원시 타입 : 정수, 실수, 문자, 논리 리터럴등의 실제 데이터 값을 저장하는 타입
참조 타입 : 객체(Object)의 번지를 참조(주소를 저장)하는 타입으로 메모리 번지 값을 통하여 객체를 참조하는 타입이다.
primitive Type
•
Null이 존재하지 않는다.
•
실제 값을 저장하는 공간으로 Stack메모리에 저장한다.
•
최대,최소 범위를 잘 지키자 언더플로우, 오버플로우가 발생할 수 있다.
•
정확한 계산이 필요할 경우에는 BigDecimal, int, long 타입중 하나를 사용해야한다. 그 이유는 실수형에서 유효자릿수를 고려하지 않는다면 오차가 발생할 수 있다. 이는 부동 소수점 방식 즉, 10진수를 정확하게 표현할 수 없으므로 발생한다.
Show All
Search
Show All
Search

Reference Type
•
기본형 타입을 제외한 타입들이 모두 참조형 타입이다.
•
Null이 존재한다.
•
값이 저장되어 있는 곳의 주소값을 저장하는 공간으로 Heap메모리에 저장된다.
•
4byte의 크기를 가진다.(객체의 주소 값)
뭔지 알겠다. 근데 조금 이상한 건 String이 없다. 그만큼 String Type은 특별하다는 것이다.
JAVA의 문자열
평소에 객체를 생성할 때는 new키워드를 사용하여 객체를 생성한다. 그러나 특이하게도 문자열은 new 연산자가 아니라 바로 값을 할당할 수 있는데 이를 문자열 리터럴이라 부른다.
리터럴?
”자바 코드에서 직접 “값”을 명시하면 리터럴로 분류할 수 있다(컴파일러가 많이 개입함).“라고 백기선님이 말했다. 알아보자.
분류할 수 있다는 점에서 상수랑의 차이점을 조금 보인다. 즉, 상수 = 변하지 않는 값,리터럴 = 데이터(변할 수 있는 값)
String name1 = new String("묵진이"); // new 연산자를 이용한 생성
String name = "묵진이"; // 리터럴 생성
Java
복사
겉보기에는 똑같은 문자열 같아 보이지만 실제로 할당되는 영역에도 차이가 난다.
첫 번째 방법인 new 연산자를 이용하는 방법은 일반 객체들처럼 Heap에 할당 된다.
두 번째 방법인 리터럴을 이용하면 String Constant Pool이라는 영역에 할당된다.
참고로 String Constant Pool의 위치는 Java 7부터 Heap 영역으로 옮겨졌다.
Java 7 이전 버전에서는 Perm 영역에 존재했다. Perm 영역은 주로 메타 데이터를 저장하는 영역으로 사용되었는데 GC의 대상에서 제외되는 영역이었다.
하지만 Java 8에 들어오면서 Perm 영역은 삭제되고 String Constant Pool은 Heap의 영역으로 이동되었다.
Heap 영역은 GC의 대상이기 때문에 String Constant Pool에서 참조를 잃은 문자열 객체들은 다시 메모리로 반환된다.
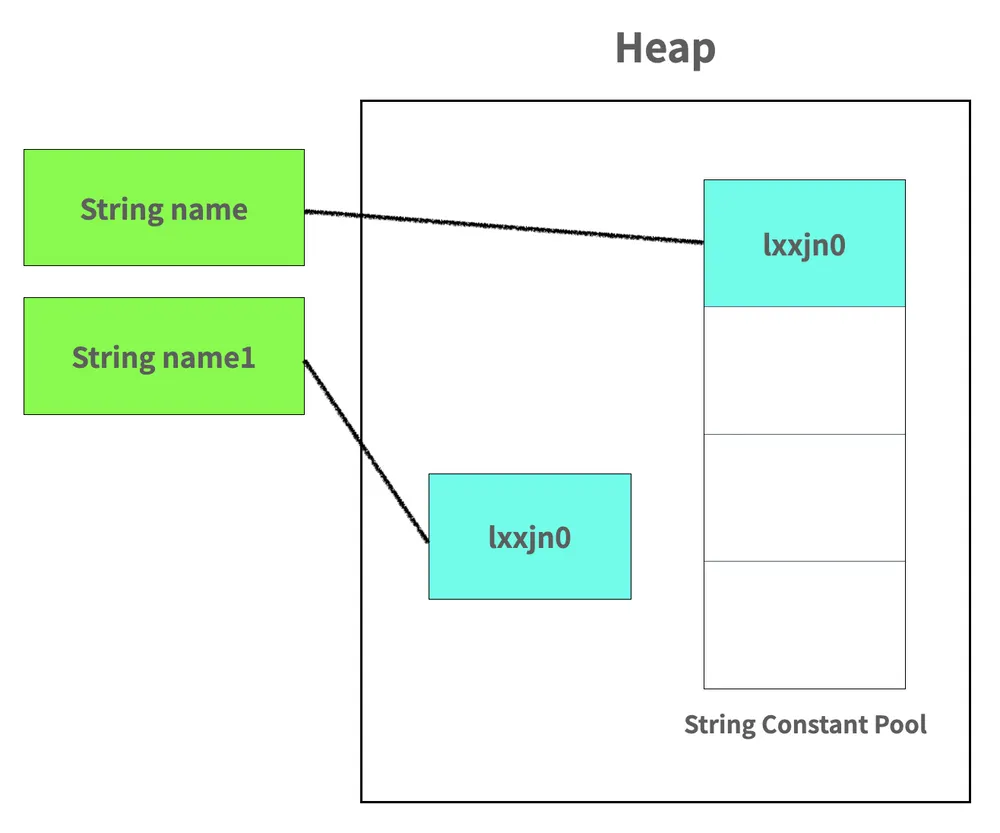
public void string() {
String name = "lxxjn0";
String name1 = "lxxjn0";
String name2 = new String("lxxjn0");
String name3 = new String("lxxjn0");
}
Java
복사



그렇다면 리터럴은 어떤 방식으로 구현 되어 있는가?
내부적으로 intern()메서드를 호출한다.
intern()의 경우 String Constant Pool에 생성하려는 문자열이 이미 존재할 경우 주소값을 받환하고 없다면 새로운 객체를 생성한 후 주소값을 반환한다(그만큼 메모리 낭비가 적어진다).
문자열 불변
자바 소스파일이 클래스파일로 컴파일되고 HVM에 올라갈 때, JVM은 String Constant Pool에 동일한 문자열이 있는지 확인하고 존재한다면 재사용하고 없으면 새롭게 만든다. 그렇기 때문에 여러 레퍼런스가 같은 문자열 리터럴을 참조하더라도 영향이 없게 만들어야하고 문자열 리터럴은 불변하기 때문에 Thread-safe하다.
그래서 문자열에 어떠한 작업을 가해서 새롭게 문자열을 만들어도 새로운 객체를 만들고 참조되는 주소만 바뀌지 원본의 String Constant Pool에 존재하는 문자열은 안 바뀐다.

요약하자면
StringBuilder를 내부적으로 String 연산에 사용한다(JDK5+ 이후로부터는). 그럼 StringBuilder없이 “+”연산만 사용해도 되는 것일까? 아니다. 결과적으로 자동으로 변환해주긴 하지만 내부적으로 버려지는 StringBuilder객체가 존재하기 때문에 적절히 써주자.
그럼 StringBuilder와 StringBuffer은 뭐가 다를까? 기능은 똑같다. 하지만 synchronized키워드가 다르다. StringBuilder의 경우 동기화가 없다 그래서 Thread-Not-Safe하다. 하지만 StringBuffer는 Thread-Safe하다. 그럼 StringBuffer만 쓰면 되겠네? 라고 생각할 수 있다. 하지만 오산이다. 결국 lock을 걸고 푸는 작업이 오버헤드가 있어서 속도가 느리다. 적절하게 사용하자.
Type Conversion
boolean형을 제외한 나머지 기본형 타입끼리는 타입 변환을 자유롭게 할 수 있다. 타입을 변환하는 방법은 묵시적 타입 변환과 명시적 타입 변환이 있다.
묵시적 타입 변환(자동, implicit conversion; 업캐스팅, up-casting)
컴파일러가 자동으로 변환한다. 데이터 손실이 발생하지 않도록 작은 범위의 타입에서 넓은 범위의 타입으로 변환할 때 즉, [byte] → [short, char] → [int] → [long] → [float] → [double] 형으로 타입 변환할 경우 이루어진다.
명시적 타입 변환(강제, explicit conversion; 다운캐스팅, down-casting)
묵시적 타입 변환이 불가능한 경우, 사용자가 강제적으로 변환한다. 즉, 넓은 범위의 타입에서 작은 범위의 타입으로 변환시키는 것이고, 이 때 데이터 손실이 일어난다.
조금 생각해본 내용
뭔가 자바도 수학 같은 느낌을 받았다. 이전에는 “=”을 단순히 “할당”으로 받아 들이고 생각했다. 근데 지금 다시 캐스팅에 대한 생각을 해보니, 수학에서의 동등, 동일 이런 느낌을 받았다. 당연히 양변을 맞춰주려면 강제적인 무엇인가가 필요하기 때문에 Type type = (Object Name) type; 이런 식으로 맞춰주는 것이 아닐까?
Type Conversion의 무릎 탁 글
유실 보장이라는 말이 즉, 묵시적 타입 변환에서의 손실이 발생하지 않는다는 말이 참 어렵게 다가왔다. 근데 이걸 보니 한방에 이해가 되었다. ‘3191’ 이라는 int형 변수를 long형으로 바꾸려고 한다. 그럼 원래 int형으로 들어갔을 땐 3바이트 까지만 사용한다. 즉, long형으로 변환해도 4~8바이트 까지 늘어나는 상황이고 나머지를 전부 0으로 바꿔주면 그만이다. 하지만 long에서 int로 가려면 기존 4~8바이트를 사용하던 메모리를 제거해야한다. 그래서 자바가 이를 자동으로 진행해주지 않는 것이다. 손실이 확실히 있는 것을 컴파일러가 인식하기 때문이다. 그래서 전적으로 개발자가 확인하라는 의미에서 명시적 타입 변환이 일어나는 것이다.
